CÁC THUẬT TOÁN TRONG PHÂN TÍCH DỮ LIỆU
Bài viết này với mục đích mang lại khái niệm cơ bản về các thuật toán trong phân tích dữ liệu (các chuyên gia nói vui là thời của toán học ứng dụng đã đến, đọc bài này các bạn hình dung rõ nét hơn)
I. Tại sao lại cần hiểu về các thuật toán trong phân tích dữ liệu
Cứ mỗi hai ngày chúng ta lại tạo ra được lượng dữ liệu tương đương với lượng dữ liệu được tạo ra từ những ngày đầu cho đến năm 2003. Vâng, là mỗi-hai-ngày. Và với việc lượng dữ liệu chúng ta đang tạo ra tiếp tục tăng nhanh, đến năm 2020, lượng thông tin số sẽ tăng từ khoảng 5 zettabyte hiện nay lên tới 50 zettabyte. Hầu hết ở mỗi hoạt động, chúng ta đều để lại một dấu vết về dữ liệu số – lướt web trực tuyến, mua hàng trong một cửa hàng trực tiếp với thẻ tín dụng, gửi e-mail, chụp một bức ảnh, đọc một bài báo trực tuyến, thậm chí cả việc dạo phố nếu bạn đang mang theo điện thoại di động hoặc có hệ thống camera giám sát CCTV trong vùng lân cận.
Thuật ngữ “dữ liệu lớn” đề cập đến việc thu thập tất cả dữ liệu đó và khả năng của chúng ta trong việc tận dụng nó để mang lại lợi thế của mình trên nhiều lĩnh vực, bao gồm cả việc kinh doanh. Bản thân dữ liệu không phải là một phát minh mới. Quay lại thời điểm trước khi có máy tính và các cơ sở dữ liệu, chúng ta vẫn sử dụng dữ liệu để theo dõi những hoạt động và đơn giản hóa các quy trình – hãy nghĩ đến các bản ghi giao dịch bằng văn bản và các hồ sơ lưu trữ bằng giấy. Máy tính, đặc biệt là các bảng tính và cơ sở dữ liệu, đã mang đến cho chúng ta một phương pháp lưu trữ và tổ chức dữ liệu trên quy mô lớn, theo một cách dễ dàng tiếp cận. Đột nhiên, thông tin đã có sẵn chỉ với một cú nhấp chuột.
Đối với việc phân tích “dữ liệu lớn” cần phải có các thuật toán tương ứng với mô hình dữ liệu và với mục đích của doanh nghiệp. Các bạn có thể tìm hiểu thêm phần chiến lược dữ liệu https://corp360.vn/chien-luoc-du-lieu.html
II. Các thuật toán trong phân tích dữ liệu
- Chuỗi thời gian (Time series)
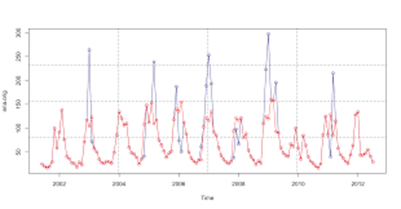
Chuỗi thời gian (tiếng Anh: time series) trong thống kê, xử lý tín hiệu, kinh tế lượng và toán tài chính là một chuỗi các điểm dữ liệu, được đo theo từng khoảnh khắc thời gian liền nhau theo một tần suất thời gian thống nhất. Ví dụ về chuỗi thời gian là giá đóng cửa của chỉ số Dow Jones hoặc lưu lượng hàng năm của sông Nin tại Aswan. Phân tích chuỗi thời gian bao gồm các phương pháp để phân tích dữ liệu chuỗi thời gian, để từ đó trích xuất ra được các thuộc tính thống kê có ý nghĩa và các đặc điểm của dữ liệu. Dự đoán chuỗi thời gian là việc sử dụng mô hình để dự đoán các sự kiện thời gian dựa vào các sự kiện đã biết trong quá khứ để từ đó dự đoán các điểm dữ liệu trước khi nó xảy ra (hoặc được đo). Chuỗi thời gian thường được vẽ theo các đồ thị.
- Hồi quy (Regression)

Đây là một phương pháp thống kê mà giá trị kỳ vọng của một hay nhiều biến ngẫu nhiên được dự đoán dựa vào điều kiện của các biến ngẫu nhiên (đã tính toán) khác. Cụ thể, có hồi qui tuyến tính, hồi qui lôgic, hồi qui Poisson và học có giám sát. Phân tích hồi qui không chỉ là trùng khớp đường cong (lựa chọn một đường cong mà vừa khớp nhất với một tập điểm dữ liệu); nó còn phải trùng khớp với một mô hình với các thành phần ngẫu nhiên và xác định (deterministic and stochastic components). Thành phần xác định được gọi là bộ dự đoán (predictor) và thành phần ngẫu nhiên được gọi là phần sai số (error term).
Dạng đơn giản nhất của một mô hình hồi qui chứa một biến phụ thuộc (còn gọi là “biến đầu ra,” “biến nội sinh,” “biến được thuyết minh”, hay “biến-Y”) và một biến độc lập đơn (còn gọi là “hệ số,” “biến ngoại sinh”, “biến thuyết minh”, hay “biến-X”).
Ví dụ thường dùng là sự phụ thuộc của huyết áp Y theo tuổi tác X của một người, hay sự phụ thuộc của trọng lượng Y của một con thú nào đó theo khẩu phần thức ăn hằng ngày X. Sự phụ thuộc này được gọi là hồi qui của Y lên X.
Hồi qui thường được xếp vào loại bài toán tối ưu vì chúng ta nỗ lực để tìm kiếm một giải pháp để cho sai số và phần dư là tốt nhất. Phương pháp sai số chung nhất được sử dụng là phương pháp bình phương cực tiểu: phương pháp này tương ứng với một hàm hợp lý dạng Gauss của các dữ liệu quan sát khi biết biến ngẫu nhiên (ẩn). Về một mặt nào đó, bình phương cực tiểu là một phương pháp ước lượng tối ưu: xem định lý Gauss-Markov.
- Phân lớp (Classification)
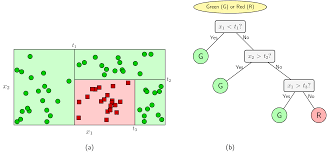
Bài toán phân lớp là quá trình phân lớp một đối tượng dữ liệu vào một hay nhiều lớp đã cho trước nhờ một mô hình phân lớp (model). Mô hình này được xây dựng dựa trên một tập dữ liệu được xây dựng trước đó có gán nhãn (hay còn gọi là tập huấn luyện). Quá trình phân lớp là quá trình gán nhãn cho đối tượng dữ liệu.
- Phân cụm (Clustering)

Một bài toán phân nhóm toàn bộ dữ liệu X thành các nhóm nhỏ dựa trên sự liên quan giữa các dữ liệu trong mỗi nhóm. Ví dụ: phân nhóm khách hàng dựa trên hành vi mua hàng. Điều này cũng giống như việc ta đưa cho một đứa trẻ rất nhiều mảnh ghép với các hình thù và màu sắc khác nhau, ví dụ tam giác, vuông, tròn với màu xanh và đỏ, sau đó yêu cầu trẻ phân chúng thành từng nhóm. Mặc dù không cho trẻ biết mảnh nào tương ứng với hình nào hoặc màu nào, nhiều khả năng chúng vẫn có thể phân loại các mảnh ghép theo màu hoặc hình dạng.
- Kết hợp (Association Rule)

Là bài toán khi chúng ta muốn khám phá ra một quy luật dựa trên nhiều dữ liệu cho trước.
Ví dụ mua cùng: những khách hàng nam mua quần áo thường có xu hướng mua thêm đồng hồ hoặc thắt lưng; dựa vào đó tạo ra một hệ thống gợi ý khách hàng (Recommendation System), thúc đẩy nhu cầu mua sắm.
Ví dụ xem cùng: Những khán giả xem phim Spider Man thường có xu hướng xem thêm phim Bat Man. Khách hàng mua máy tính thì thường có thói quen tìm hiểu các dòng máy tính trước khi mua, việc tìm hiểu này thì thường theo cấu hình vd: khi mua máy Dell cấu hình RAM 8g, ổ Cứng 500G thì coi máy HP, Asus.. có cấu hình tương đương. Vì thế các trang thương mại điện tử thường có chức năng xem cùng, như với bài toán mua máy tính ở trên, khi khách hàng xem máy Dell thì hệ thống liệt kê các máy tương ứng để khách hàng có nhiều lựa chọn và tăng khả năng mua hàng.
Sản phẩm







Tin tức








